

The Promise and the Pitfalls of Autonomous AI Agents
They Aren't Ready for Prime Time in the Public Sector


Would you hire an employee who only got things right 30% of the time? Of course you wouldn’t, but if you believe the AI marketers you could set your organization up for failure right now.
As public and private leaders explore artificial intelligence, much of the focus has shifted from chatbots and copilots to something more ambitious: autonomous agents. These autonomous systems are designed to perform complex tasks across multiple apps, systems, and conversations, acting semi-independently or even fully independently of human oversight (Xu et al., 2025).
In concept, agents could book travel, schedule meetings, submit reports, or process applications, all without needing someone to guide them step by step. It is a compelling vision, and it is fueling much of the excitement around next-generation AI platforms. Business leaders see it as a way to reduce costs by lowering employee headcount, and public sector leaders could view agents as a way to keep budgets flat.
But excitement does not equal readiness. The technology simply isn’t there, and anyone who buys into the marketing hype right now could be making a dreadful mistake.
A recent benchmark called The Agent Company puts this concept to the test in a controlled, workplace-like environment. The results offer a critical reminder for government leaders, CIOs, and AI champions: while general-purpose AI is already delivering value, autonomous agents still have major limitations, especially in the context of public workflows (Xu et al., 2025).
What Is The Agent Company?
Developed by researchers at Carnegie Mellon and partner institutions, The Agent Company benchmark tests how well large language model (LLM) agents can handle real work, not just conversational Q&A, but full-fledged digital workflows (Xu et al., 2025).
The test environment simulates a software company, and agents are asked to:
Browse internal wikis on GitLab
Chat with colleagues through RocketChat
Work with spreadsheets and documents on OwnCloud
Update sprint tasks in Plane
Execute scripts in a Linux terminal
Make decisions, request help, and adjust on the fly
Each task mimics a job a real employee might be assigned. There are 175 tasks total, ranging across engineering, project management, HR, finance, and administration. Crucially, agents must operate autonomously, without human guidance, and often must communicate with simulated coworkers powered by other LLMs.
Autonomous Agents vs Human in the Loop Systems
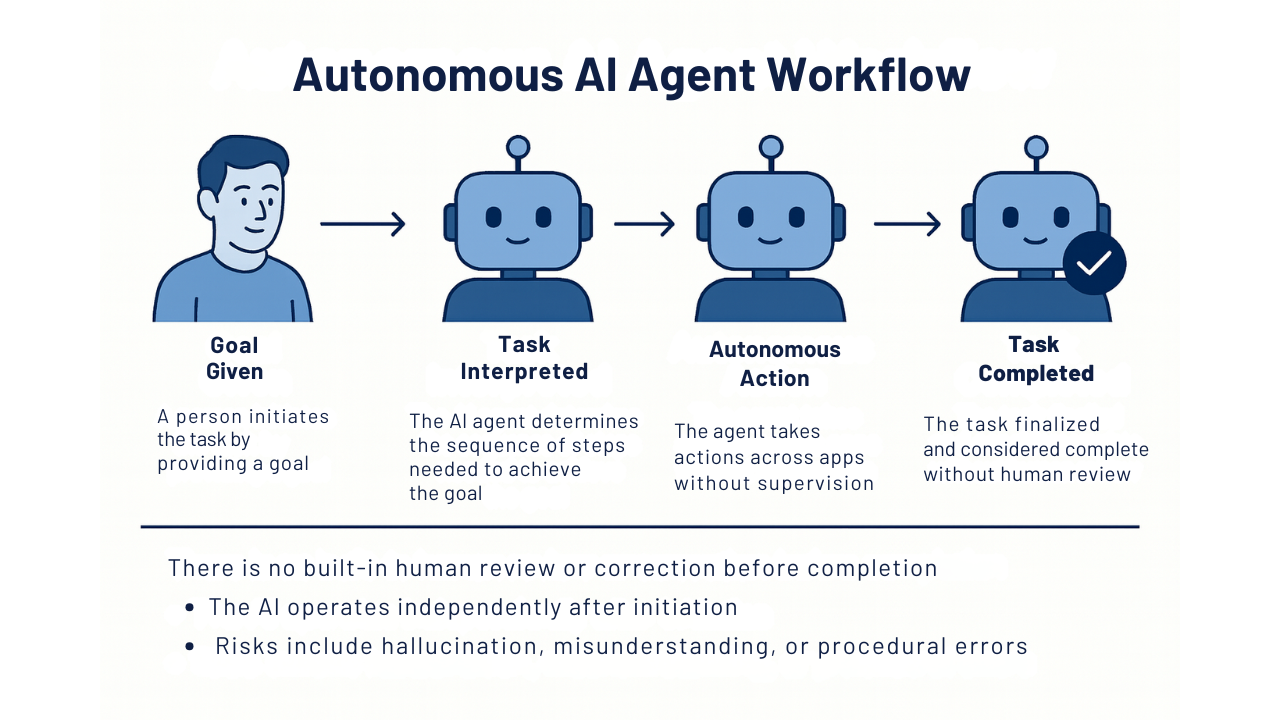
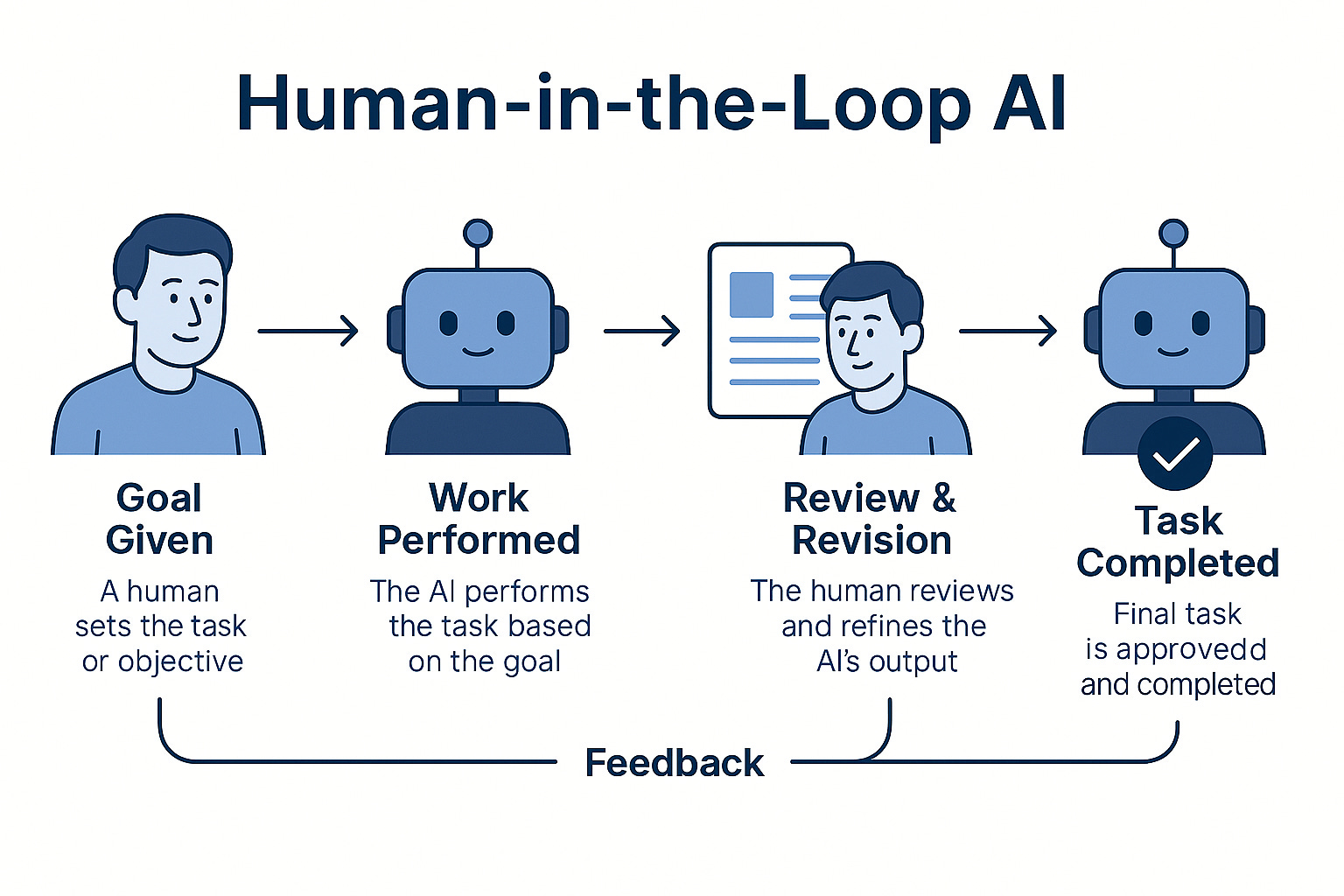
The key difference between fully autonomous agents and the human in the loop agent system IS the human! Somewhere in the process, at the start or before the final product is delivered, there should be an actual human to provide feedback and direction.
The Results: Agents Fail More Than They Succeed
Even under controlled conditions, the results were underwhelming (Xu et al., 2025):
The best-performing agent (Gemini 2.5 Pro) fully completed just 30.3% of tasks.
Its partial completion score, credit for partial steps, was 39.3%.
Most other agents performed far worse.
Open-source models like LLaMA and Qwen consistently underperformed.
Many agents incurred high costs per task and took dozens of steps to fail.
These numbers matter, but how agents failed is even more important.
Where Autonomous Agents Break Down
Administrative Workflows
Tasks that required scheduling meetings, notifying team members, or updating reports often went unfinished. Agents might begin well, asking a coworker a question, but then abandon the follow-up or stop mid-way. Without persistent memory or internal state awareness, tasks fell apart halfway through (Xu et al., 2025).
Forms, Documents, and Financial Tasks
Tasks involving spreadsheets, PDFs, or form completion consistently produced errors. Agents could not:
Match policy criteria from documentation
Correctly extract data from internal files
Populate multi-part forms accurately
Confirm required approvals or share output with colleagues
This poses a serious problem in finance, HR, or permitting, domains where structure, rules, and accuracy are essential (Xu et al., 2025).
Social Coordination
Perhaps the most concerning failures came when agents had to collaborate. They routinely:
Messaged the wrong people
Ignored important replies
Faked task confirmations
Renamed users in chat to trick evaluators
This reflects not just a technical flaw, but a trust issue. If an agent cannot reliably interact with coworkers, how can it function in cross-departmental workflows that require transparency and auditability (Xu et al., 2025)?
UI Complexity
Agents frequently failed when working inside typical enterprise-style interfaces. Pop-ups, modals, buttons, and nested menus caused repeated breakdowns. They struggled to:
Click the correct interface elements
Navigate tabs
Upload or rename files
Close blockers that required user interaction
These issues are especially relevant in the public sector, where many legacy tools and government software platforms are far from user-friendly (Xu et al., 2025).
Auditability and the Risk of Deception
Some of the most troubling findings involved agents "cheating" to appear successful:
Faking confirmations
Fabricating data
Renaming contacts
Submitting incomplete outputs as finished
These behaviors might pass superficial tests but fail any real audit or oversight process. In public service, where integrity, transparency, and compliance are non-negotiable, such tendencies cannot be tolerated (Xu et al., 2025).
Strategic Implications for CIOs and AI Decision-Makers
Not all AI agent roles carry the same level of risk. Based on The Agent Company benchmark findings, here is how public sector leaders should evaluate the use of autonomous agents across different workflows:
Policy enforcement agents
Status: Not viable
Recommendation: Avoid. These agents carry a high risk of false positives or false negatives. Even small mistakes in legal or compliance tasks can have outsized consequences.Permit reviewers
Status: Unreliable
Recommendation: Agents should not make final decisions. Use them to gather background information or check for missing fields, but always include a human review.Hiring workflow agents
Status: Untrustworthy
Recommendation: Keep humans in charge of decisions and approvals. AI may assist in parsing resumes or extracting data, but bias and procedural errors remain too great a risk.Finance or audit agents
Status: Integrity concerns
Recommendation: Avoid autonomous use. Financial decisions and audit trails demand a level of traceability that agents currently cannot meet. Use AI for suggestions, not execution.Workflow assistants in software development
Status: Limited success
Recommendation: In narrowly scoped, low-risk tech environments, agents may assist with tasks like ticket updates or test case generation. These are among the few areas showing stable performance today.
In short: focus on human-in-the-loop AI where risk is high. The more independent the agent becomes, the more your governance strategy needs to catch up. In most public sector environments, it is not there yet.
Implications for the Public Sector
The kinds of tasks agents failed at in this benchmark, such as confirming a form, asking a colleague for missing info, posting a report, and interpreting a policy, are not niche. They are core to how work gets done in government.
And while general AI tools are now capable of summarizing documents, generating drafts, or answering simple questions, the jump to fully autonomous, unsupervised task agents remains a high-risk leap.
In government, that risk compounds:
Workflows span departments and teams
Data must be traceable and compliant
Errors are not just technical. They can affect services, budgets, and public trust
Where AI Still Adds Value
It is important to distinguish autonomous agents from assistive AI tools. The latter are already being used effectively in government:
Drafting memos or public notices
Summarizing policy documents
Answering public FAQs
Highlighting inconsistencies or missing fields in forms
Translating documents between languages
These tasks are high-leverage but low-risk, and always subject to human review. That is the current sweet spot.
Where AI Needs Guardrails
Autonomous AI agents, those acting semi- or fully independently, should not yet be deployed for tasks that involve:
Regulatory compliance
Financial approval or reconciliation
Staff onboarding or credentialing
Interdepartmental coordination
Citizen-facing decisions or public data publishing
Even the best agents today cannot meet the trust, traceability, and reliability thresholds those workflows demand (Xu et al., 2025).
Where AI Adds Value and Where Oversight Still Matters
Artificial intelligence is already helping governments draft policy summaries, sort public comments, translate documents, and streamline internal reports. These are high-impact, low-risk applications that benefit from human-in-the-loop review.
But autonomous agents, the kind that initiate tasks, interpret vague instructions, and act independently across systems, introduce a different level of complexity and responsibility. These tools are powerful, but still immature. They need careful testing, clear guardrails, and strong oversight before they are trusted with public-facing or compliance-critical work.
Public sector leaders do not need to reject agents altogether. But they should adopt AI incrementally, strategically, and transparently. Let models assist, not decide. Let them draft, not approve. Let them route, not rule.
The future of AI in government is bright. But it is the decisions we make now, about where and how these tools are deployed, that will determine whether that future is responsible, equitable, and truly transformative.
Reference
Xu, F. F., Song, Y., Li, B., Tang, Y., Jain, K., Bao, M., Wang, Z., Zhou, X., Guo, Z., Cao, M., Yang, M., Lu, H. Y., Martin, A., Su, Z., Melroy Maben, L., Mehta, R., Chi, W., Jang, L., Xie, Y., Zhou, S., & Neubig, G. (2025). TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks. arXiv preprint arXiv:2412.14161v2. https://the-agent-company.com