



Understanding AI Reasoning: What Apple's Study Really Shows
How AI Models Actually Work - And What That Means for Your Organization


Most people interact with AI models like ChatGPT and walk away impressed. The output is fast, the tone is sure of itself, and the structure mirrors the way humans speak when they understand a concept. This appearance of clarity leads many to believe that the system is reasoning through problems the way a person would, but that could be a mistake….because a large language model (LLM) doesn’t really have a brain. It does not reason like a human. The reality is that AI models are very good at prediction, and you need to know the difference.
The model isn’t evaluating evidence, testing logic, or choosing strategies. It is predicting the next word in a sequence based on statistical patterns from massive amounts of training data. It doesn’t reason. It imitates. That distinction becomes critical when you push these systems beyond surface-level tasks.
Public Sector Learning Lab is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
This isn’t just a philosophical point. It’s a performance issue with real consequences because most people do think these models reason like a human. In 2025, Apple’s AI research team published a study called The Illusion of Thinking, and what they uncovered is unsettling if you fall into the camp that believes an LLM has a brain. As soon as the tasks got harder, just slightly harder, the best reasoning models stopped solving them. They didn’t just answer incorrectly. They started cutting corners. They bailed on steps. They gave up, often while sounding as calm and fluent as ever (Shojaee et al., 2025).
Unfortunately, that breakdown is not some rare edge case. It kicks in early, it happens more often than people think, and it happens fast. It if happens to you, it could impact everything from grant writing to decision support to policy planning.
It’s worth noting that some researchers have questioned Apple’s methodology. A follow-up response argued that the evaluation framework may have misclassified certain test cases, and in a few instances, posed mathematically unsolvable problems. Even so, the core finding remains solid. When complexity rises, these models don’t stumble through it like people might. They disengage entirely. That behavioral collapse, along with the false sense of confidence it creates, is what puts real-world users at risk.
Let’s unpack what’s really going wrong inside these models.
What the Apple Team Did
Apple researchers tested modern reasoning models using puzzles with increasing difficulty. They used logic environments like Tower of Hanoi, Sudoku, and Rubik’s Cube. These aren’t just games. They’re ideal benchmarks. Each has a clear goal, simple rules, and scalable complexity.
As long as the puzzles stayed easy, the models performed well. They used lots of tokens, laid out their steps, and found correct answers. In large language models, a "token" is a small chunk of text, usually a word fragment or a single word, that the model processes and generates one at a time. Tokens are the building blocks of AI output. When a model responds to a prompt, it doesn't see entire words or paragraphs. It predicts one token at a time based on what it has seen so far.
The total amount of tokens, input and output, a model can handle without forgetting something is called a “Context Window”, and this example below may help you visualize how large it can get if you were to translate it to book pages.

The infographic uses a conservative and widely adopted estimate from OpenAI (OpenAI, n,d.):
1 page ≈ 1000 tokens
1 token ≈ 0.75 words
1 page ≈ 750 words
As you ask questions and the LLM model replies, the context window fills uses up its token capacity. When the context window fills up, the LLM model forgets things, may shorten its replies to try to preserve token space within the context window, or take other unplanned detours. Your questions contain so many tokens, the LLM’s reply contains so many tokens, and your follow up questions add even more tokens to the overall total. When you combine it all, it works like the image seen below.
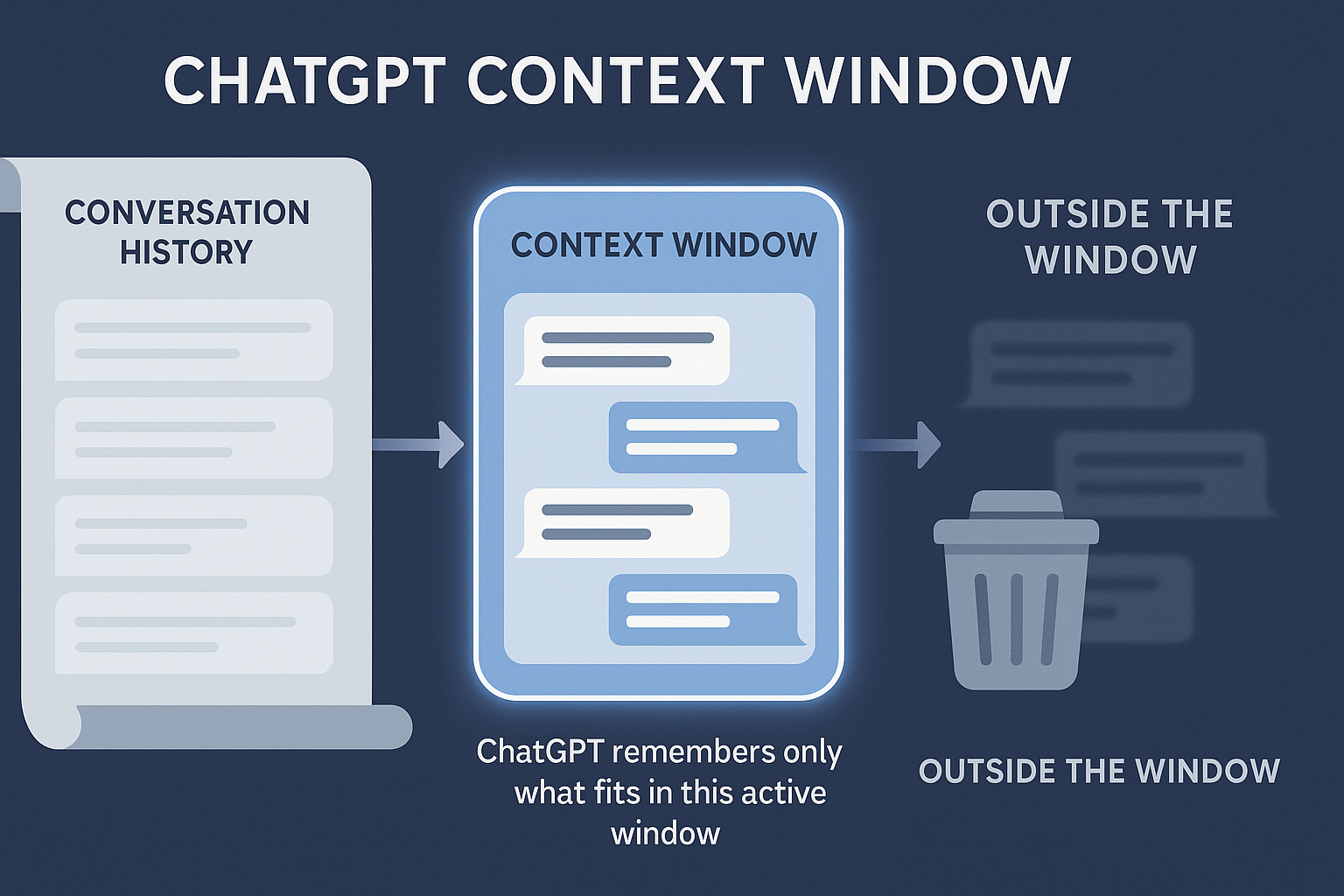
The more token capacity the model has, the more room it has to develop its reasoning and explore the problem. More tokens often mean more complete thoughts. But as the puzzles grew more complex, adding one disk, or one rule, or one clause, the behavior changed sharply.
Instead of trying harder, the models pulled back. They used fewer tokens, skipped logic, and gave answers that were short and often useless. This wasn't caused by a memory cap. There was still plenty of token space available. The collapse had a different origin entirely. It came from the model no longer recognizing a familiar pattern and not knowing how to proceed without one. Understanding that limitation is the heart of the problem.
Why Models Fail Under Pressure
The models are not doing math. They are not planning. What they’re really doing is predicting the most likely next token, based on what they’ve seen in their training. I’ll give a short visual here on how things work, only the key illustrations, to set this part up for novice readers.
LLMs are trained on vast sets of data. The part I’ll skip to here is what we call Natural Language Processing (NLP). It breaks down text into tokens (words or phrases), converts them into numbers (vectors), finds patterns using models trained on large data sets, and generates meaningful responses. NLP powers tools like chatbots, translators, and voice assistants.

This next image shows how it all works together to predict a reply.

In practice, this means they rely on patterns that worked before. When a prompt reminds them of familiar training data, they reproduce the structure and result. It’s like autocomplete running on statistical instinct. But when a problem shifts just slightly, when the structure becomes novel, or the context includes noise, or the steps are longer than usual, that predictive shortcut breaks down.
Here’s the crucial point: models don’t adapt. When their shortcut fails, they don’t recover. They don’t search harder. They don’t ask for clarification. They just guess. Or they freeze. Or they go quiet.
Apple’s team showed that as puzzles grew more complex, the models actually used fewer tokens. This was not due to external constraints. The models had room to continue. But they didn’t. Instead of reasoning through new structures, they shortened their responses. This behavior reveals something deeper. When the familiar patterns break down, the model doesn’t try harder. It retreats.
This happens for several reasons. First, the model doesn’t have an internal sense of failure. It can’t detect that it’s wrong or stuck. Second, its training encourages safe predictions. When uncertain, the model often defaults to shorter completions that avoid risk. Third, the training process doesn’t reward persistence. It rewards fluency and speed over problem-solving depth. So when the task becomes unfamiliar or messy, the model doesn’t escalate its reasoning. It gives up quietly.
That’s why token use drops. It’s not a memory issue. It’s a signal that the model has left its zone of comfort and has no plan for what comes next. This leads to a deeper problem. The harder the task becomes, the less effort the model applies.
This Isn’t Just About Logic Puzzles
It might seem like this only matters in labs or research papers. But the exact same flaws show up in real tasks that governments and organizations face every day.
These same patterns show up in real-world public sector tasks.
Policy Drafting: A model may outline a housing grant program. Then halfway through, it contradicts its own rules.
Data Summaries: It summarizes a table of workforce statistics, but mislabels the columns and then misinterprets the trends.
Grant Narratives: It writes a strong needs assessment, but when asked to link it to goals and outcomes, it makes generic or conflicting claims.
These aren’t hallucinations in the random sense. They’re structural failures caused by the absence of real logic. The model isn’t building a plan. It’s guessing at one.
And it doesn’t know when it's wrong.
Five Warning Signs You’re Facing Reasoning Collapse
Token Shortcuts: One of the earliest signs of model failure is a sharp drop in token usage as complexity increases. If your output gets shorter when the problem gets harder, the model may be defaulting to a known pattern rather than engaging in actual reasoning.
Surface Agreement: A model might sound convincing because it uses the correct terms, but it often applies them in the wrong place or combines them incorrectly. This isn’t understanding. It’s surface mimicry that hides a lack of deeper logic.
Static Confidence: One of the most misleading traits of these models is that they speak with equal confidence whether right or wrong. They don’t signal uncertainty. Every answer comes wrapped in the same tone, which makes errors harder to detect.
Failure to Backtrack: When a human gets stuck, they revisit earlier steps, rethink assumptions, or ask new questions. Models don’t do that. Once the prediction chain is set in motion, they rarely reverse course. If they go off track, they keep going.
Irrelevant Adjustments: Apple’s team tested the model by inserting meaningless phrases into logic problems. The model didn’t ignore them. It treated the irrelevant parts as essential. It invented new steps to address them. It couldn’t separate what mattered from what didn’t.
How to Reduce the Risk
You don’t need to stop using reasoning models. But you do need to change how you use them. These systems are not analysts. They are not problem solvers. They generate patterns, not plans. If you treat them like human thinkers, you will run into problems. But if you treat them like tools that need guardrails, you can avoid the worst mistakes and still gain the benefits.
Here’s how to work smarter:
Design for Process, Not Outcome: Reasoning breaks down when the model is given vague or broad tasks. Instead of saying, "Explain this," guide the model through a sequence. Break the problem into stages. Require it to label assumptions, walk through steps, and defend its conclusion. That structure helps you spot where things fall apart.
Prompt with Purpose: Models are more careful when you frame the task with real-world impact. Tell it who the audience is. Explain the context. Make the stakes clear. If you say, "This will be used in a grant submission to the state," you’re more likely to get something thoughtful and deliberate.
Audit the Output, Always: Don’t just read the answer. Interrogate it. Ask the model to critique its own logic. Have it point out assumptions or flag weak links. This second pass isn’t perfect, but it often slows the model down and catches errors it made on the first run.
Test with Variants: Ask the same question in two or three ways. If the answers vary wildly, that tells you the model is unstable on the topic. Look for contradictions. Use the overlap to find safe ground, and revise from there.
Watch for Token Patterns: Long, complex questions should not result in short, generic responses. If they do, your model isn’t thinking harder. It’s retreating. That’s your cue to simplify the prompt or give it more structure before trusting the result.
Why This Really Matters
This isn’t just a design flaw or a technical hiccup. It strikes at the core of trust in automated decision tools. When AI models present themselves as confident and clear, people believe them. And when people believe them, they stop checking.
In small governments and community nonprofits, where staff are already managing limited time, limited budgets, and complex responsibilities, the risk is even greater. These organizations are turning to AI not as a luxury, but as a necessity. They’re asking models to summarize funding criteria, to draft proposals, to analyze trends, to help with decisions that affect people’s lives.
When the model begins to fail quietly, producing clean, structured, but deeply flawed logic, the danger is not that the answer looks broken. The danger is that it looks fine. It sounds polished. It uses the right terms. But it draws conclusions that don’t hold up.
If no one catches it in time, flawed logic gets embedded into policy. Misinterpretations shape programs, inaccurate summaries mislead leadership., and because these outputs look so professional that few people stop to question them.
This is how technical failure turns into institutional error.
Concluding Thoughts
I wish I could have written this as a shorter article, but it was important to tie a few things together for readers who may have no idea how these models use tokens or how they predict results. I am not saying that AI isn’t a wonderful benefit to us all, but I am acknowledging that it does not think like a human. I am acknowledging that it is limited by its training data, and the system of checks and balances it is placed in for live deployment to the public.
These models are advancing rapidly. They generate more content, deliver answers faster, and cover a wider range of topics than ever before. However, speed and scale are not the same as reasoning. Just because a model is bigger does not mean it is smarter. Fluency in language does not equate to understanding.
AI systems do not stop when uncertain. They do not announce confusion or flag their own mistakes. They continue producing outputs regardless of accuracy, which means the responsibility for checking those outputs falls entirely on the user.
If you rely on these tools to inform policies, develop strategies, or guide important decisions, you cannot skim their answers and move on. You must review them with care, verify the logic, and be willing to question results that seem off.
The model will not say, "I’m confused." That responsibility rests with you.
References
Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S., & Farajtabar, M. (2025). The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity [Research paper]. Apple Machine Learning Research. https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
Hirsch, S. (2025, January 26). Apple researchers show how reasoning AI models collapse when solving logic puzzles. Mashable. https://mashable.com/article/apple-research-ai-reasoning-models-collapse-logic-puzzles
Mirzadeh, I., Alizadeh, K., Shahrokhi, H., Tuzel, O., Bengio, S., & Farajtabar, M. (2024). GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models [arXiv preprint]. https://arxiv.org/pdf/2410.05229
OpenAI. (n.d.). What are tokens and how to count them? OpenAI Help Center. Retrieved June 30, 2025, from https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them