



Using Leaderboards to Assess AI Agents
Making AI Work for Government: Why the Galileo Leaderboard Matters


The Galileo AI Agent Leaderboard
AI agents marks one of the most transformative developments in government technology in recent history. As local, state, and federal agencies continue to explore AI as a way to streamline operations, lower costs, and expand service access, the question of how to evaluate and select the right AI models has become increasingly urgent. The Galileo AI Agent Leaderboard answers this need by providing a transparent, field-tested benchmarking tool that focuses on enterprise use cases. These use cases include those that mirror everyday government operations.
From Lab Results to Real-World Value
Traditional academic benchmarks such as MMLU or HellaSwag evaluate reasoning, factual recall, or knowledge breadth. Galileo flips that model by prioritizing practical application. It assesses how well language models function as agents in business-like settings, offering more relevant insights for agencies managing complex workflows. Hosted on Hugging Face Spaces, the leaderboard currently exists in two iterations. Version 2, launched in mid-2025, was explicitly designed for enterprise-scale evaluation (Bhavsar, 2025a).
Rather than limiting evaluation to theory-based tasks, Galileo’s framework introduces five domains banking, healthcare, investment, telecommunications, and insurance, that reflect the transactional, regulated, and multi-turn nature of most public sector work. These domains serve as close analogs for areas like social services, permitting, public health administration, and citizen engagement.
Measuring What Matters: Action and Tool Use
Two primary metrics drive Galileo's evaluation approach: Action Completion (AC) and Tool Selection Quality (TSQ).
Action Completion (AC): This metric determines whether an AI agent can fulfill all of a user’s goals throughout a complete interaction. For public agencies, this could simulate an agent guiding a constituent through applying for housing assistance or filing a complaint that requires back-and-forth clarification. It evaluates end-to-end reliability and interaction success.
Tool Selection Quality (TSQ): Here, the focus shifts to how intelligently the agent selects and applies external tools, such as APIs, databases, or internal systems. Using chain-of-thought prompting and secondary verification from models like GPT-4o-mini, TSQ evaluates whether tools were used when needed and avoided when unnecessary (Galileo, 2024).
The Galileo Method: A Real-World Simulation Engine
Galileo’s methodology goes far beyond simple prompt-and-response testing. Each agent is placed into 100 synthetic scenarios per domain, simulating enterprise-grade environments with:
Multi-turn dialogues that span 5 to 8 connected user goals
Role-played user personas with varying communication styles
Tool simulators replicating backend systems
Edge cases, ambiguity, and real-time memory dependencies
The agents are tested using a consistent pipeline that includes the model-under-test, a user simulator, and a mock backend tool environment. This approach enables apples-to-apples comparisons while capturing the unpredictable nature of real-world interactions (Bhavsar, 2025b).
The entire benchmark is open-source. Code, scenarios, and results are all publicly available, offering governments a level of transparency rarely seen in enterprise software evaluation (rungalileo, 2025).
Early Results: A Caution Against One-Size-Fits-All
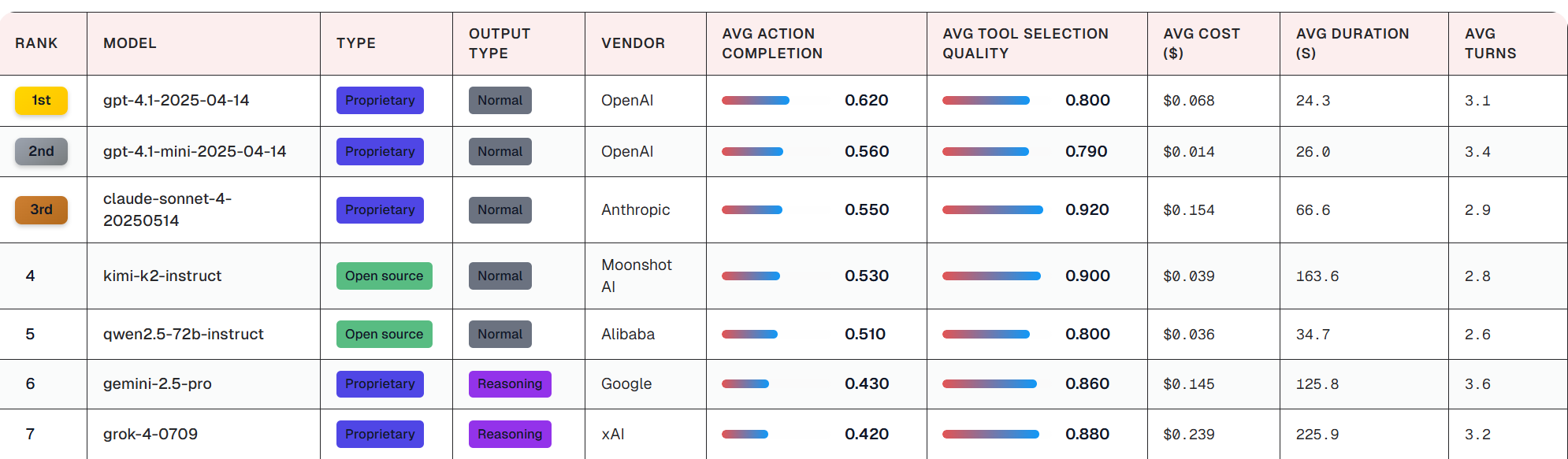
The July 2025 Galileo report illustrates that no single model leads across all metrics. GPT-4.1 tops Action Completion with a 62 percent score, making it the most reliable in completing full conversations. However, Gemini-2.5-flash leads Tool Selection with an impressive 94 percent score but finishes with only a 38 percent AC (Bhavsar, 2025c).
For public agencies, this means a strategic choice: If the goal is completing citizen interactions end-to-end, GPT-4.1 may be preferable. If integrating backend systems efficiently is more important, Gemini may shine. This reinforces a critical principle—model selection should align with operational needs, not popularity.
Cost-performance comparisons further illustrate this point. The mini version of GPT-4.1, for example, delivers nearly identical tool accuracy for one-fifth of the cost ($0.014 per session vs. $0.068), making it more accessible for smaller agencies (AI Multiple Research, 2025).
Why This Matters for Public Sector AI Governance
Government AI adoption is not simply a technical shift. It is a governance challenge that demands transparency, predictability, and fiscal prudence. The Galileo Leaderboard offers distinct advantages in each area:
Transparency: Open code and datasets allow public organizations to validate claims and understand scoring criteria. This supports auditability and informed oversight.
Risk Management: Stress-testing models against complex, ambiguous scenarios surfaces potential failure points before deployment, reducing liability and disruption.
Cost Rationalization: Agencies can make data-driven trade-offs between accuracy and affordability.
Predictive Value: Because scenarios closely mimic real workflows, the results offer more reliable performance forecasting than abstract tests like knowledge Q&A (Evidently AI, 2025).
Strategic Recommendations for Public Agencies
Governments looking to deploy AI agents should take a phased, informed approach to integration, guided by Galileo’s benchmark data.
Match Model to Use Case: No model is best at everything. Use Galileo to match domain-specific results to your agency’s actual needs—like permit processing or benefits eligibility screening.
Start Small, Then Scale: Begin with narrow, structured tasks where outcomes are easy to measure. Expand only after validating performance across metrics.
Monitor and Adapt Continuously: Galileo updates monthly. Establish an internal process for reviewing leaderboard shifts to avoid lock-in to declining or stagnating models.
Train Leadership on Benchmark Literacy: Decision-makers should understand what AC and TSQ mean in their specific context to avoid vendor hype or misalignment.
A New Standard for Public AI Decision-Making
Galileo is not the only evaluation framework, but it is currently one of the most grounded in enterprise and operational relevance. While academic benchmarks measure theoretical intelligence, Galileo assesses real productivity.
Its alignment with enterprise AI governance frameworks, including risk registers, cost modeling, and tool interoperability, makes it particularly useful for public sector IT, procurement, and compliance teams (Hyper AI, 2025).
As models evolve, Galileo will continue to refine how it scores, simulates, and compares AI agents. For public sector leaders, this means an increasingly trustworthy tool to inform not just which models to use, but how to deploy, budget for, and govern them effectively.
Concluding Thoughts
Public sector leaders need evaluation tools built for the world they operate. Lab evaluates are great, but we need to see how these agents work in a real world setting before we can truly determine their value. The Galileo AI Agent Leaderboard meets that need with open standards, domain realism, and actionable insights.
It is more than a scoreboard. It is a decision-support system for public agencies that are committed to thoughtful, transparent, and cost-effective AI adoption. Governments that learn to read and apply these benchmarks will be better equipped to deliver digital services that are not only innovative but responsible and resilient.
References
AI Multiple Research. (2025, July 10). AI agent performance: Success rates & ROI in 2025. https://research.aimultiple.com/ai-agent-performance/
Bhavsar, P. (2025a, February 11). Introducing our agent leaderboard on Hugging Face. Galileo AI Blog. https://galileo.ai/blog/agent-leaderboard
Bhavsar, P. (2025b, July 17). Launching agent leaderboard v2: The enterprise-grade benchmark for AI agents. Hugging Face Blog. https://huggingface.co/blog/pratikbhavsar/agent-leaderboard-v2
Bhavsar, P. (2025c, July 18). Launching agent leaderboard v2: The enterprise-grade benchmark for AI agents. Galileo AI Blog. https://galileo.ai/blog/agent-leaderboard-v2
Evidently AI. (2025, July 11). 10 AI agent benchmarks. https://www.evidentlyai.com/blog/ai-agent-benchmarks
Galileo. (2024, August 14). Tool selection quality. Galileo Documentation. https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-selection-quality
Hyper AI. (2025, July 17). Galileo AI launches enterprise-grade benchmark for language models. https://hyper.ai/en/headlines/d6a1bfa7b09d241763181ab9efb4cece
rungalileo. (2025, February 10). Agent leaderboard: Ranking LLMs on agentic tasks. GitHub. https://github.com/rungalileo/agent-leaderboard